


Imagine navegar em um oceano de informações. A internet está cheia de dados abertos e públicos, que se multiplicam a cada segundo. Saber buscar, transformar e interpretar esses dados pode ser um divisor de águas para empresas que buscam vantagem competitiva ou meramente ampliar a compreensão sobre cenários de mercado. O processo de automação desta coleta tem um nome: extração automatizada de dados web – ou, como muitos conhecem, scraping.
Mas afinal, como tirar proveito desse universo sem cair em armadilhas técnicas ou legais? Este guia traz respostas, exemplos do cotidiano de negócios e alerta para polêmicas envolvendo privacidade e transparência. Prepare-se para conhecer as principais técnicas e soluções, além de dicas valiosas para navegar com segurança neste universo.
Por que extrair dados públicos da web faz sentido
Cada site, cada rede social, cada base de dados pública esconde oportunidades. Informações sobre preços, tendências, dados cadastrais e situações fiscais alimentam todo tipo de decisão comercial ou estratégica. Seja para montar um estudo de mercado do zero, monitorar concorrentes, criar sistemas de recomendação de produtos ou esclarecer riscos, coletar e organizar esses dados é fundamental.
Talvez você já tenha precisado copiar manualmente listas, números ou textos de dezenas de páginas. É lento, suscetível a erros e costuma ser uma tarefa que consome tempo e energia.
Automatizar muda tudo de patamar.
Scrapers (robôs coletores) conseguem repetir milhares de cliques, buscas e extrações em minutos, alinhando produtividade e rastreabilidade. Mas isso é só o começo da história...
O que é web scraping e qual seu papel atualmente
O termo web scraping refere-se ao processo de recuperação, transformação e armazenamento automático de informações disponibilizadas em páginas web. A técnica envolve um robô ou script que simula a navegação de um usuário, captura elementos estruturados ou não (tabelas, textos, imagens, metadados) e organiza tudo em formatos práticos: planilhas, bancos de dados, relatórios ou feeds de aplicação.
O nome pode carregar certo peso, mas é bom lembrar:
- Muita informação disponível online é pública, criada para consumo aberto.
- A extração nem sempre é invasiva. Utilizar APIs abertas é um exemplo de acesso responsável e transparente.
- Decisões baseadas em grandes volumes de dados tendem a ser mais rápidas e confiáveis.
Para ilustrar: plataformas como a Direct Data oferecem meios de acesso a centenas de fontes, conectando dados públicos a ferramentas práticas de análise.
Principais técnicas de extração de dados e suas diferenças
Nem todo processo de coleta digital é igual. O método escolhido depende do objetivo, da natureza dos dados e da infraestrutura técnica. Veja algumas das abordagens mais adotadas:
- Raspagem direta do HTML: Scripts leem o código-fonte da página, filtrando e extraindo só o necessário.
- Crawling: Um robô navega em diversos links de um ou mais domínios, mapeando e estrutura conteúdos amplos.
- Consumo de APIs: O acesso por APIs (Application Programming Interfaces) costuma ser mais estável, ético e eficiente para dados atualizados.
 Cada técnica possui vantagens e desafios. Por exemplo, scraping HTML pode ser rápido, mas quebra facilmente quando o site muda sua estrutura. Crawling pode gerar grande volume de requisições — essencial cuidar para não sobrecarregar servidores terceiros. Já APIs, quando públicas, são o caminho natural para obter dados limpos, organizados e sem ruídos legais.
Cada técnica possui vantagens e desafios. Por exemplo, scraping HTML pode ser rápido, mas quebra facilmente quando o site muda sua estrutura. Crawling pode gerar grande volume de requisições — essencial cuidar para não sobrecarregar servidores terceiros. Já APIs, quando públicas, são o caminho natural para obter dados limpos, organizados e sem ruídos legais.
Ferramentas que impulsionam a coleta automatizada
A escolha da solução técnica certa faz diferença desde o início. Ferramentas são desenvolvidas para simplificar o processo e aumentar a escalabilidade. Algumas ganham destaque por sua robustez ou facilidade de uso.
- Scrapy: Framework Python open-source que permite criar rastreadores (crawlers) e raspadores (scrapers) altamente personalizados. Conhecida por sua flexibilidade e potencial para operações em larga escala, como citado pelo portal Scrapeless.
- Soluções no-code: Plataformas que permitem montar fluxos de extração arrastando blocos ou pré-programando agentes, como os Atores do Apify, listados como destaque em 2025 pelo Bright Data. Elas democratizam o acesso mesmo para quem não sabe programar — basta seguir os passos, indicar a origem e ajustar o formato de saída.
- Extensões de navegador: Pequenos plugins que capturam campos de formulários, tabelas e listas em segundos, direto do seu browser.
- Soluções SaaS: Como a Direct Data, permitem consultas, integração via API e download de grandes bases, tudo com baixo esforço técnico.
- Ferramentas em nuvem: Executam coletas em servidores remotos, evitando bloqueios por IP e mantendo performance constante mesmo em operações prolongadas.
Automação é sinônimo de escala – e velocidade, claro.
Desafios técnicos no processo de extração
Às vezes o plano parece perfeito. Você cria o script, acha que tudo será simples... mas aparecem obstáculos. Sites podem implementar técnicas para impedir robôs, como bloqueio de IP, detecção por user-agent, limitação de frequência por requisição, ou aquele velho conhecido: captcha.
- Alteração frequente do layout: Pequenas mudanças no HTML já podem quebrar seu coletor.
- Conteúdo dinâmico: Muitos dados só aparecem após execução de scripts, exigindo robôs capazes de interpretar JavaScript, como Selenium ou Puppeteer.
- Captchas e bloqueios: Desafios para confirmar se o acesso é humano. Superar isso demanda criatividade, mas também respeito aos limites.
Além disso, um estudo de Jens Foerderer, publicado em agosto de 2023, observa que procedimentos ingênuos podem introduzir viés de amostragem, distorcendo conclusões e prejudicando estratégias. Volatilidade do conteúdo, personalização e dados ocultos são fatores críticos que merecem atenção extra durante a coleta.
 Como contornar obstáculos técnicos
Como contornar obstáculos técnicos
A experiência ensina alguns atalhos – e ressalta a necessidade de equilíbrio. Várias estratégias são conhecidas:
- Rotação de IPs: Evita bloqueios por repetição de requisições do mesmo endereço.
- Mudança de User-Agent: Simula dispositivos e navegadores diferentes a cada acesso.
- Delays aleatórios: Programar intervalos imprevisíveis reduz riscos de bloqueio massivo.
- Integração com APIs oficiais, sempre que possível: Minimiza riscos técnicos e legais.
- Ferramentas de proxy e servidores em nuvem: Descentralizam o esforço e aumentam a resiliência da coleta.
Claro, um olhar responsável precisa prevalecer. Muitas vezes, insistir em burlar bloqueios agressivos pode soar antietico – e até ilegal, dependendo do contexto. E vale lembrar: transparência e respeito aos termos de uso nunca são opcionais.
Questões legais e éticas: limites do jogo
Nem tudo que é tecnicamente viável é aceitável do ponto de vista legal. Countries como o Brasil adaptaram leis de privacidade, propriedade intelectual e uso de dados para proteger indivíduos e coletivos.
No coração da discussão, aparecem temas como:
- Consentimento: Dados pessoais, mesmo que publicados, ainda podem estar protegidos por LGPD ou outras legislações semelhantes.
- Termos de uso: Muitas páginas deixam claro que coleta automatizada está proibida, exceto via canais oficiais.
- Privacidade: A distinção entre dados públicos e dados sensíveis requer atenção, sempre.
- Uso responsável: O propósito da coleta (análise, enriquecimento, monitoramento) pode definir o risco envolvido.
 A OWASP entende que a segurança das aplicações web é um desafio que envolve cultura, processos e tecnologia — e destaca a necessidade de melhorias contínuas para garantir proteção eficaz (comunidade OWASP). Ao automatizar coletas, é preciso cuidar para não violar direitos ou comprometer reputações. Isso vale para empresas de todos os tamanhos.
A OWASP entende que a segurança das aplicações web é um desafio que envolve cultura, processos e tecnologia — e destaca a necessidade de melhorias contínuas para garantir proteção eficaz (comunidade OWASP). Ao automatizar coletas, é preciso cuidar para não violar direitos ou comprometer reputações. Isso vale para empresas de todos os tamanhos.
Legalidade sem ética pode não bastar; ética sem legalidade, também não.
Usos práticos do scraping no mundo dos negócios
O fascínio pela automação só faz sentido quando retorna em insights e decisões rápidas – em ambientes cada vez mais competitivos. Empresas recorrem à extração de dados para:
- Análise de concorrentes: Coletar preços, promoções, lançamentos de produtos e posição em rankings de busca.
- Prospecção de leads: Identificar clientes potenciais a partir de cadastros públicos ou redes sociais.
- Monitoramento de reputação: Mapear citações, reclamações ou avaliações em sites e fóruns.
- Atualização cadastral: Cruzar dados de fontes oficiais para evitar fraudes e duplicidades.
- Compliance e risco: Analisar relações fiscais, pendências e históricos públicos.
Plataformas como a Direct Data permitem extrair, enriquecer e higienizar bases para acelerar análises e apoiar decisões baseadas em fatos. Ela integra centenas de fontes a fluxos práticos de inteligência, simplificando todo o processo para times de crédito, cobrança ou vendas.
Sistemas de bloqueio e defesa dos websites
Sites investem para se proteger. A implementação de mecanismos anti-bot é cada vez mais sofisticada, desde captchas estáticos até desafios baseados em interação real. O uso de fingerprints, análise de padrões de acesso e bloqueios via firewall são recursos comuns.
Estes mecanismos não existem por acaso. O tráfego robótico é capaz de consumir recursos, afetar análises, distorcer indicadores e até causar prejuízo financeiro ― principalmente quando afeta e-commerces, mecanismos de busca e bancos de dados governamentais.
Por isso, cada tentativa de coleta deve buscar equilíbrio entre necessidade, respeito aos limites técnicos e obediência à legislação.
O papel das APIs públicas e privadas na extração ética
As APIs surgem como caminho preferencial para consumo de dados públicos, já que são padronizadas, robustas e, acima de tudo, autorizadas. Muitas empresas e órgãos já oferecem interfaces abertas, com acesso documentado e controlado, para consultas legítimas.
Usar APIs reduz riscos de erro, minimiza possíveis conflitos legais e garante estabilidade de integração. Mas nem sempre todo dado público está disponível por API. Nestes casos, a alternativa da raspagem direta deve considerar limitações e responsabilidades.
Na Direct Data, por exemplo, diferentes APIs estão conectadas para consulta de fontes fiscais, cadastrais e reputacionais, com centralização dos dados e interface simples para análise. É o melhor dos dois mundos: automação responsável e resultado rápido.
Sempre que possível, escolha o caminho oficial. APIs são suas aliadas.
Tipos de scrapers e suas aplicações cotidianas
Não existe um único perfil de coletor. Algumas soluções batem de frente com desafios complexos, enquanto outras servem bem para tarefas menores. Vamos aos principais tipos:
- Softwares tradicionais: Instalados localmente, oferecem controle total, mas exigem configuração e manutenção.
- Extensões de navegador: Práticas para tarefas rápidas, funcionando diretamente via Chrome, Firefox ou outros browsers.
- Soluções em nuvem: Executam coletas em servidores remotos, com escalabilidade elástica conforme a necessidade.
- Plataformas SaaS: Como a Direct Data, trazem painéis prontos para consulta, integração API e download, sem a necessidade de investir em infraestrutura interna.
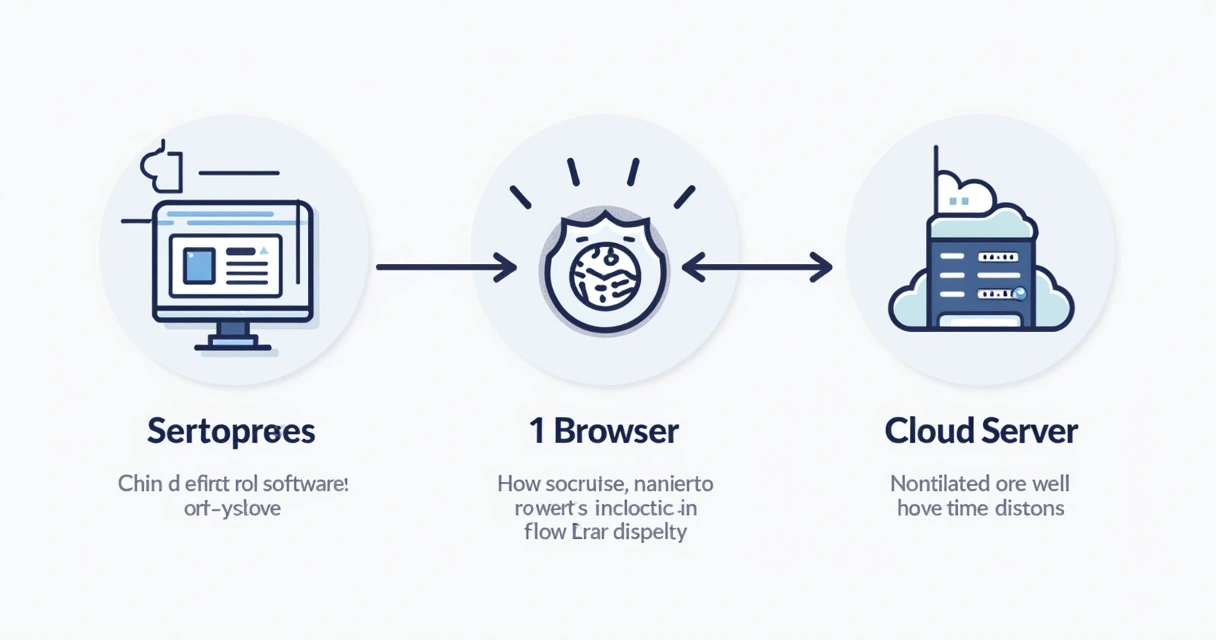 Não existe um único jeito certo — o ideal é alinhar objetivo, orçamento, recursos técnicos e grau de automação desejado.
Não existe um único jeito certo — o ideal é alinhar objetivo, orçamento, recursos técnicos e grau de automação desejado.
Quem pode se beneficiar da extração automatizada de dados?
Qualquer organização interessada em evoluir processos, apoiar decisões com fatos ou detectar oportunidades de negócio pode se beneficiar. Profissionais de risco, crédito, vendas, marketing, compliance, desenvolvimento de produtos e até jornalismo encontram valor no acesso rápido a dados abertos.
- Empresas de todos os portes: Desde quem quer validar um ou cem mil cadastros até grandes players monitorando o mercado inteiro.
- Agentes de crédito e cobrança: Para verificar, enriquecer e atualizar informações sobre clientes e fornecedores.
- Consultores e analistas: Para montar painéis, relatórios especiais e análises de tendências.
- Setores públicos e privados: Corrupção, gestão transparente ou controles internos, todos ganham com acesso ágil a dados relevantes.
Com o crescimento do volume e variedade de informações públicas, contar com recursos automatizados — sem abrir mão do respeito à legislação — tornou-se diferenciais para quem busca agilidade e segurança.
Possíveis riscos e limitações
Apesar de toda promessa, a extração automatizada não é livre de riscos ou falhas. Como mostrado no estudo de Jens Foerderer, é possível encontrar vieses nos dados, seja pela limitação do escopo coletado, alteração do conteúdo original ou bloqueios gerados pelo próprio site-alvo.
Outro ponto: operações massivas, desrespeitando limites técnicos, podem causar banimento, bloqueios por IP ou até responsabilização jurídica. Por isso, toda estratégia precisa balancear volume, velocidade e aderência às normas.
Confiabilidade exige método – e humildade para rever escolhas.
Conclusão
No universo digital, competir e inovar depende cada vez mais da capacidade de transformar dados públicos dispersos em inteligência concreta. Scraping, crawlers e o uso de APIs ampliam o acesso, trazem agilidade e reduzem erros de análises manuais. Mas não basta automatizar; é preciso entender limitações técnicas, agir de modo responsável e conhecer o que é permitido (ou não) em cada contexto.
Plataformas como a Direct Data estão disponíveis para mostrar o potencial da decisão baseada em dados. Ao automatizar verificações de cadastro, enriquecer bases de leads ou estudar movimentações do mercado, você pode ganhar tempo, reduzir riscos e identificar oportunidades. Use nossos R$25,00 em créditos para testar o serviço e descubra como tornar seus processos mais rápidos e seguros – tudo dentro da lei. O futuro é de quem sabe extrair inteligência dos dados certos, no momento certo.
Perguntas frequentes
O que é web scraping?
Web scraping é o processo de coletar dados automaticamente de páginas da web, utilizando scripts ou softwares que simulam a navegação humana, identificam e extraem informações presentes no conteúdo dos sites para posterior análise, armazenamento ou integração com outros sistemas.
Como fazer extração de dados públicos?
A extração de dados públicos pode ser feita acessando APIs oficiais, utilizando ferramentas automatizadas como crawlers ou scrapers, ou ainda por meio de plataformas SaaS que ofereçam integração facilitada. Sempre respeite as limitações técnicas, termos de uso do site e diretrizes legais.
Web scraping é legal no Brasil?
O scraping de dados públicos pode ser legal, desde que não infrinja direitos autorais, privacidade ou termos de uso claros. Dados pessoais são protegidos pela legislação, como a LGPD. Cada caso precisa ser analisado à luz da finalidade e do tipo de informação extraída.
Quais são as melhores APIs para scraping?
As melhores APIs são aquelas que oferecem dados confiáveis, atualizados e condições transparentes de uso, como APIs governamentais, de órgãos reguladores e de empresas especializadas em integração de dados. Sempre prefira APIs oficiais e autorizadas, que além de mais seguras, são estáveis e documentadas.
Vale a pena usar web scraping?
Sim, especialmente quando a necessidade é agilizar a coleta de grandes volumes de informações públicas, identificar tendências e apoiar decisões data-driven. Porém, é importante estar atento à legislação vigente e garantir que o método utilizado seja ético, seguro e confiável.


